
Я познаю текст
Человечество на протяжении своего существования находит закономерности в том, что происходит с ним вокруг. А там, где есть закономерность, можно создать систему. Это относится и к текстам, к их восприятию.
Текст, при написании которого копирайтер продумал не только стиль повествования и информационный состав, но и семантику текста, будет с большей долей вероятности соответствовать условиям ранжирования поисковых алгоритмов.
Законы семантических джунглей
Среди SEO-специалистов распространено мнение, что алгоритмы Яндекс и Google для оценки текстового содержимого разработаны с применением законов, которые сформулированы еще во второй половине XX века. И конечно, при разработке ТЗ для очередного seo текста, оптимизаторы руководствуются принципами этих законов. Рассмотрим некоторые ключевые (придется коснуться математики).
Закон Ципфа
Закон Ципфа выведен экспериментальным путем в начале прошлого века французским стенографистом Жан-Батист Эсту, а эмпирически подтвержден лингвистом Джорджом Ципфом в 1949 году. Гласит, что ранг (или порядковый номер) употребляемого слова обратно пропорционален (не точно, а приблизительно) частоте его использования в тексте.
Например, если взять и разложить по порядковым номерам слова, в зависимости от частоты в тексте, то можно получить результат, представленный в виде гиперболы с длинным хвостом, где:
- Верхняя, первая точка — это слова первого ранга, встречающиеся в тексте наиболее часто;
- Вторая точка — это слова второго ранга, которые, как окажется в ходе подсчета, имеют частоту приблизительно вдвое меньшую, чем слова первого ранга;
- Третья точка — это слова третьего ранга, которые будут иметь частоту приблизительно втрое меньшую, чем слова первого ранга.
И так далее…
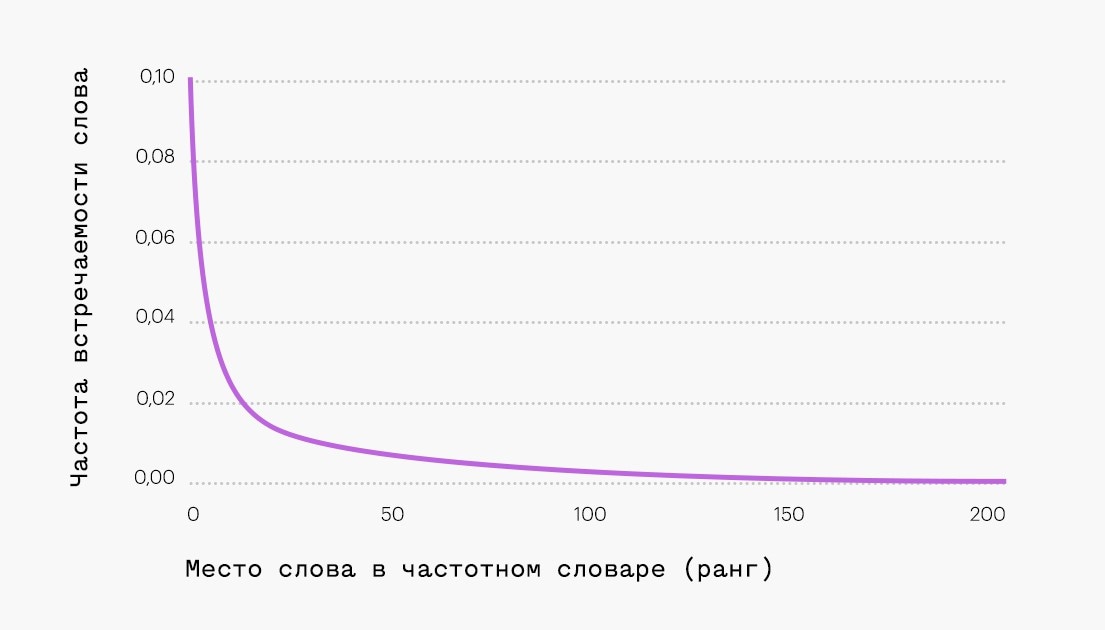
Эта закономерность установлена эмпирическим путем при исследовании обычных текстов. Однако в случае с seo-текстами, их нельзя назвать «обычными», и в большинстве случаев они имеют отклонения от закономерности распределения слов по Ципфу. Поэтому в наше время, когда поисковые алгоритмы все жестче фильтруют неестественные тексты «не для людей» и понижают их в выдаче, есть большая вероятность, что закон Ципфа учитывается ими при ранжировании.
Следовательно, при написании очередного оптимизированного для поисковых систем текста, желательно сверяться с соответствием закону Ципфа. Нужно это для того, чтобы не допустить так называемый переспам — переизбыток вхождения слов, особенно ключевых запросов.
Хотя закон Ципфа по отношению к семантическому разбору текста является динамическим (то есть, его можно применить во всех случаях), со стороны математиков нередки случаи его критики. Но, не смотря на критику, все же большинство специалистов сходятся во мнении, что закон может быть ориентиром для написания естественных seo текстов.
Закон Хипса
Похожий на закон Ципфа, согласно которому количество уникальных слов в тексте имеет зависимость от его длины. Только в этом случае длину можно представить в виде функции.
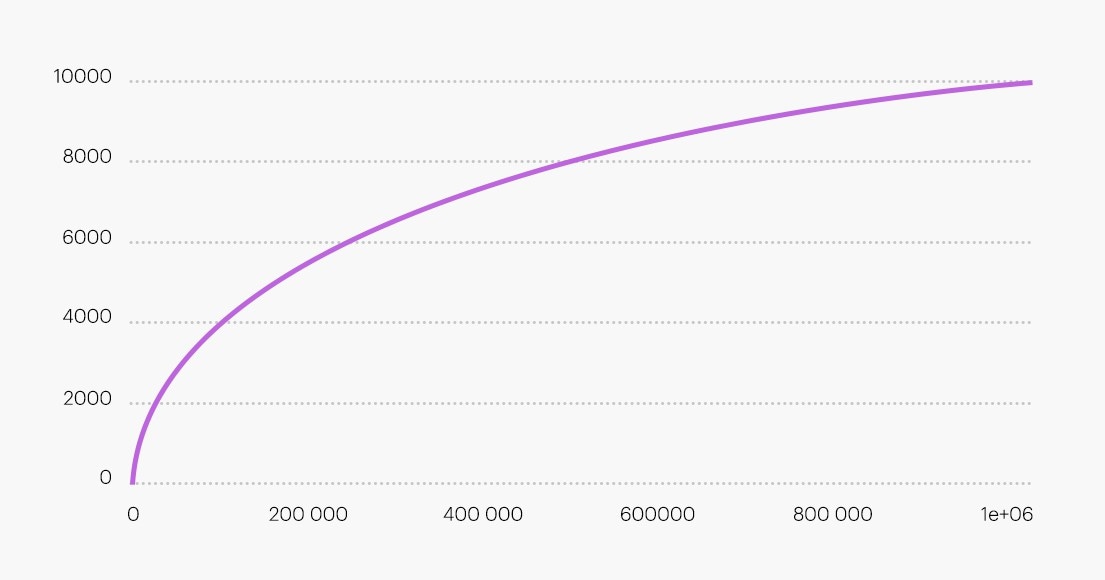
Это также может служить ориентиром для написания качественных «естественных» текстов.
Описанные 2 закона входят в алгоритмы большинства сервисов для проверки текстов на тошноту и переспам.
Примеры таких сервисов:
Все для людей
Также, есть информация, что при анализе контента поисковики оценивают его удобочитаемость. Впрочем, почему нет, если можно выявить закономерность и выразить в формуле? Для оценки удобства восприятия текста могут применяться:
Индекс Флеша
Самый распространенный. В формуле используется средняя длина предложения (СДП) и среднее число слогов (СЧС).
Индекс Флеша = 206.835 − (1.3 × СДП) − (60.1 × СЧС)
Чем выше полученный индекс, тем легче читать текст.
Индекс туманности Ганнинга, Фог-индекс
Также используется в настоящее время для оценки восприятия текста, — насколько он легок и лишен «туманности».
Формула для расчета индекса туманности Ганнинга, адаптированная для русского языка:
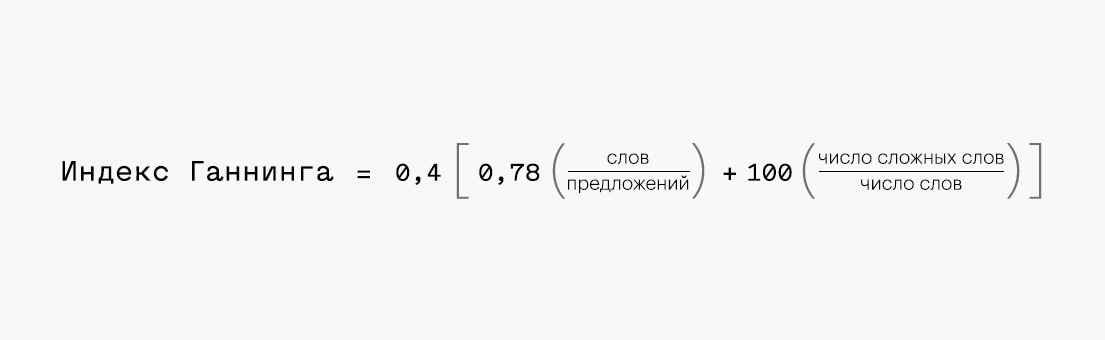
Для расчета рекомендуется взять кусок текста на 100-200 слов. Сложносочиненные предложения считаются за два. Сложные слова содержат 3 и более слогов.
Проверить текст на удобочитаемость можно, например, в сервисе ru.megaindex.com
Поисковые роботы настроены «мыслить» как люди, поэтому описанные закономерности и формулы если и не применяются в явном, прямом виде, то уж точно являются прообразом для составляющей оценочных алгоритмов.
Как это работает
Доподлинно это неизвестно. Используется огромная формула, которая состоит из многих других более мелких.
Известны только общие принципы работы алгоритмов анализа текстов. Детали являются тайной, возможно даже для самих разработчиков, так как сейчас алгоритмы самообучаются, используя нейронные сети.
Известно, что:
- Яндекс лучше понимает словоформы запроса, чем Google. Алгоритм Google сознательно игнорирует их, согласно заявлению представителей, для максимально точного результата обработки запроса и получения выдачи;
- Оба поисковика сейчас используют нейронные сети с целью их самообучения для лучшего понимания намерения пользователя при запросе, его смысла;
- Также поисковые алгоритмы сейчас намного дружественнее к запросам в разговорной форме благодаря алгоритмам «Палех» и «Королев» в Яндексе и «Колибри» в Google;
- Яндекс более требователен к уникальности текста и его естественности. Хотя в результатах выдачи на первых позициях еще встречаются страницы с откровенно переоптимизированными текстами, но в таких случаях срабатывают другие факторы (коих тысячи);
- Первым делом поисковые роботы анализируют title, затем заголовок H1 с текстом, и оценивают их релевантность друг другу;
- Самые страшные фильтры у поисковых систем для сайтов с плохими текстами — «Панда» у Google и «Баден-Баден» у Яндекса. За размещенный текст низкого качества на одной странице под фильтр может попасть сразу весь сайт. Признаки попадания сайта под фильтр: резкое падение позиций и трафика без каких-либо явных причин после очередного апдейта индекса поисковой системы.
Как выйти из семантической матрицы и взломать поисковую систему
Никак 😀 Точнее, можно использовать методы из старой школы SEO, вроде спама ключевыми запросами, но если и что-то «взлетит», то совсем ненадолго, и упадет уже очень низко. Остается только процитировать Капитанов «Очевидность» (имеются в виду представители поисковых систем): «Создавайте уникальный и интересный контент, пишите естественные тексты для людей, а не для машин. Кажется, в Pitcher так могут».
Всегда рады помочь вам в продвижении ваших товаров или услуг в сети Интернет! Если вопросы остались, то пишите love@pitcher.agency или звоните нам +7 (800) 200-69-20



